Il fait tourner une IA sur un vieux Mac de 2005… Et vous, qu’attendez-vous ?
1 Go de RAM pour faire tourner un LLM ? Oui.

Utilisez-vous régulièrement des outils d’IA générative, comme ChatGPT ou Gemini ? Si c’est le cas, sachez qu’il est possible de construire votre propre chatbot personnalisé à la maison ! Cela semblait, il y a un an à peine, inaccessible au commun des mortels, mais désormais, plusieurs solutions s’offrent à vous si vous souhaitez vous lancer.
L’outil Ollama (non, il n’est pas développé par Mistral) permet par exemple de facilement faire tourner un grand nombre de modèles de langage en local, depuis votre ordinateur, . L’inconvénient est qu’il faut une carte graphique Nvidia dotée d’une capacité d’au moins 6 Go pour obtenir des résultats convenables. Pourtant, un ingénieur logiciel nommé Andrew Rossignol vient de prouver qu’on peut faire tourner une IA sur un vieux Mac datant de 2005 !
Une prouesse technique sur un PowerBook G4
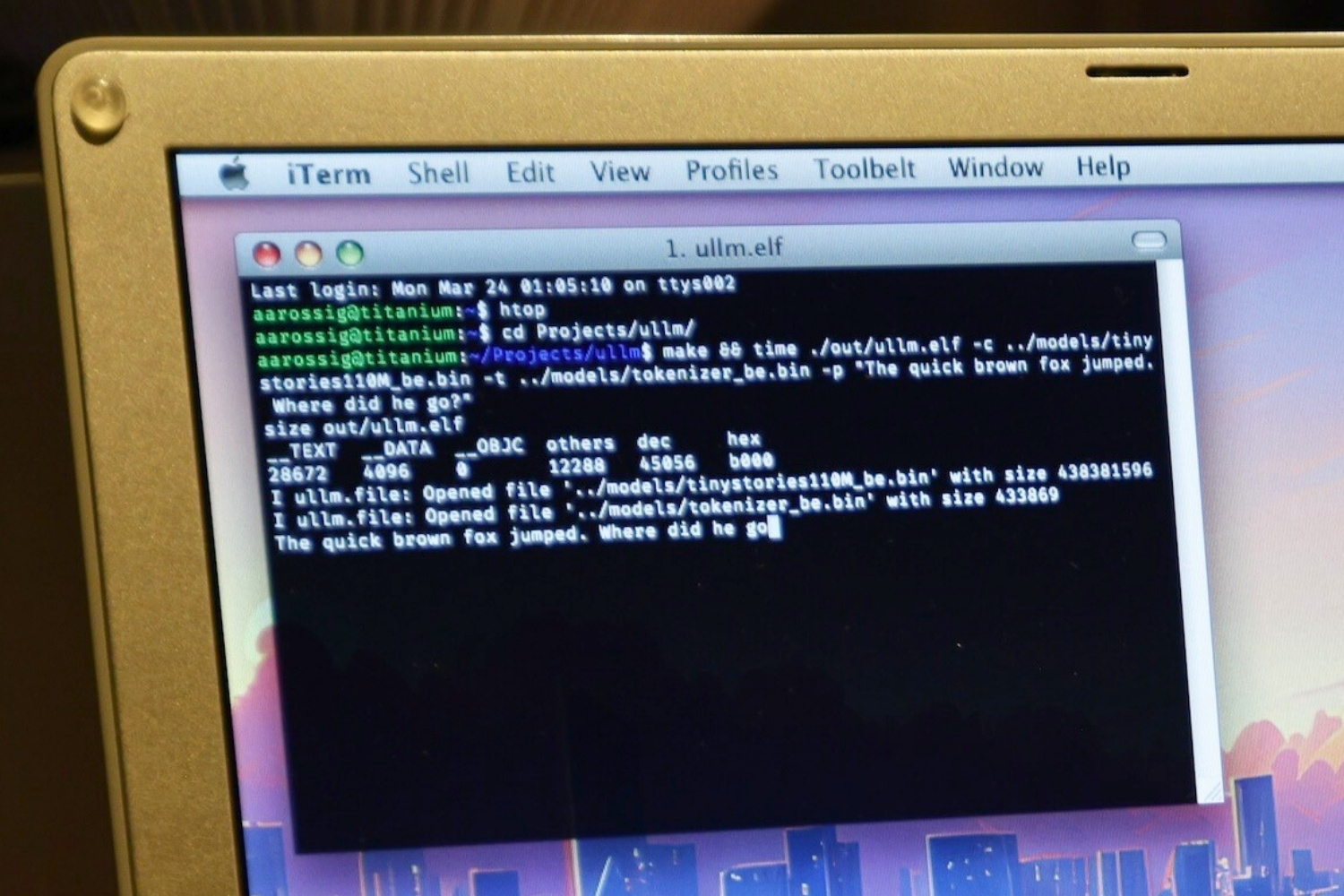
Équipé d’un modeste processeur PowerPC à 1,5 GHz et d’un unique Go de RAM, le PowerBook G4 d’Andrew Rossignol semblait bien mal parti pour exécuter un modèle de langage moderne. L’ingénieur a pourtant réussi l’exploit en portant le projet open-source llama2.c sur cette machine vintage.
Le défi était de taille : adapter un code initialement prévu pour des processeurs x86 à architecture Intel à un vieux PowerPC. Andrew a dû gérer des problèmes d’endianness (ordre des octets), d’alignement mémoire et optimiser les performances en exploitant les extensions vectorielles AltiVec du PowerPC.
© Andrew Rossignol
Des résultat impressionnant malgré des limites
Après de nombreux efforts, Andrew est parvenu à faire tourner un modèle Llama 2 « TinyStories » de 110 Mo sur son PowerBook. Certes, l’inférence est 8 fois plus lente que sur un processeur moderne, avec seulement 0,88 token généré par seconde, mais le simple fait d’y arriver sur une machine de 20 ans d’âge est une véritable prouesse.
Bien sûr, les limites sont nombreuses. Impossible de charger des modèles plus conséquents, l’espace mémoire adressable étant limité à 4 Go sur cette architecture 32 bits. Cette expérience ouvre cependant des perspectives intéressantes pour démocratiser l’IA, même avec du matériel ancien. Elle prouve qu’avec un peu d’ingéniosité, on peut faire tourner une IA sur à peu près n’importe quelle machine !
Et si vous construisiez votre propre ChatGPT maison ?
Si vous disposez d’une carte graphique NVIDIA avec au moins 6 Go de VRAM, c’est possible grâce à des outils comme Ollama, Open WebUI et ComfyUI. Cette combinaison vous permet de créer votre propre assistant IA local, capable de générer du texte, de faire des recherches internet, ou même de créer des images à partir de simples descriptions. Exemple :
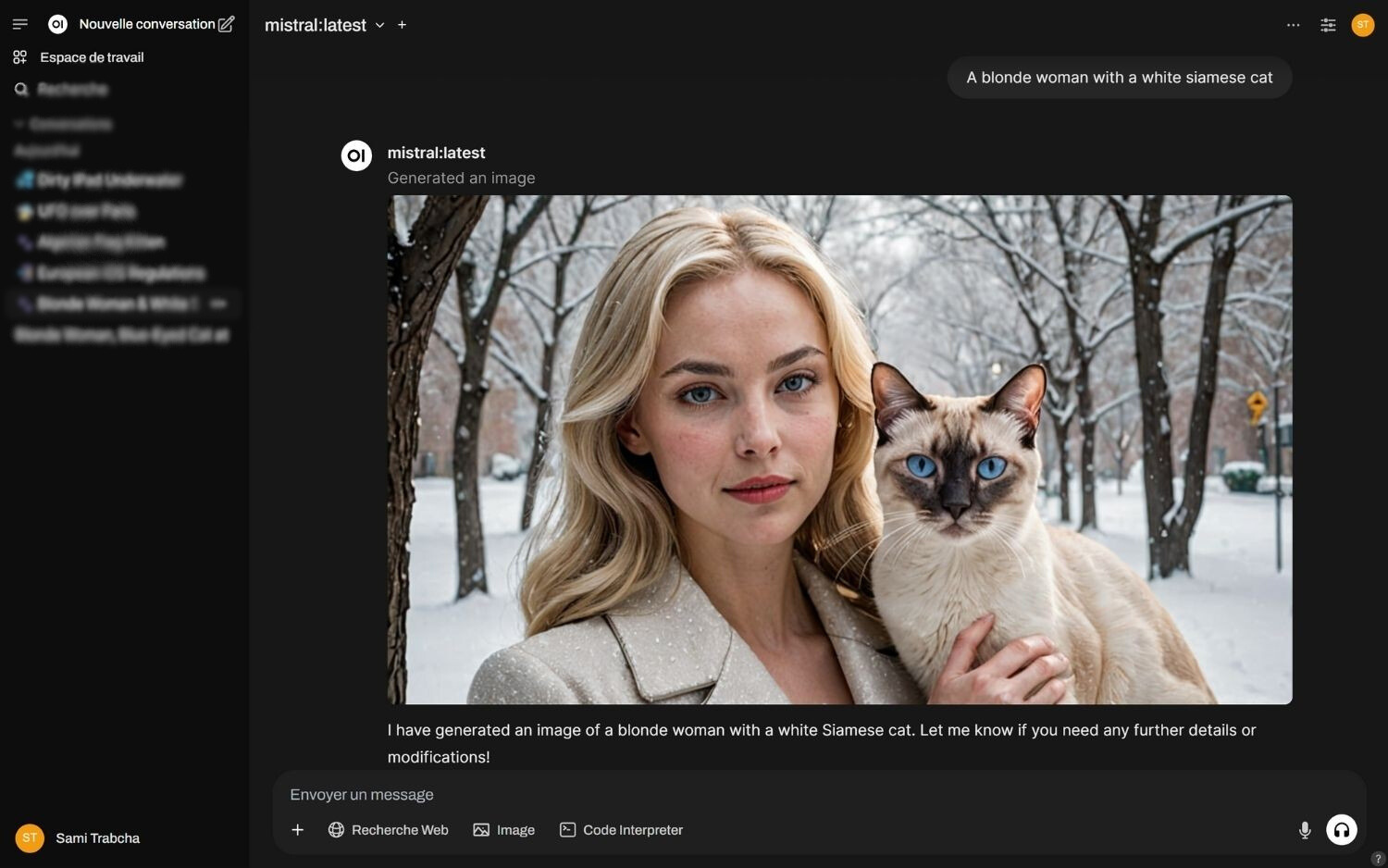
© iPhon.fr / Sami Trabcha – application ChatGPT maison
Tout cela fonctionne en local, dans des conteneurs Docker faciles à déployer, sans abonnement, sans dépendance à une API, et avec une interface similaire à ChatGPT (en utilisant Open WebUI). Vous pouvez même l’alimenter avec vos propres documents et lui en apprendre plus sur vous même et votre travail, pour qu’il s’adapte.
Sur Mac ? Oui, les utilisateurs de Mac Apple Silicon peuvent aussi s’y essayer. Ollama fonctionne nativement sur macOS avec accélération GPU via Metal, mais certains outils comme ComfyUI restent nativement réservés aux GPU NVIDIA. Il faudra donc faire preuve de souplesse et de curiosité technique.